
imágenes falsas
El martes, Microsoft Anunciado un nuevo modelo de lenguaje de IA liviano y disponible gratuitamente llamado Phi-3-mini, que es más simple y menos costoso de operar que los modelos de lenguaje grande (LLM) tradicionales como OpenAI. GPT-4 Turbo. Su pequeño tamaño es ideal para ejecutarse localmente, lo que podría ofrecer un modelo de IA de capacidad similar a la versión gratuita de ChatGPT a un teléfono inteligente sin necesidad de una conexión a Internet para ejecutarlo.
El campo de IA normalmente mide el tamaño del modelo de lenguaje de IA mediante el recuento de parámetros. Los parámetros son valores numéricos en una red neuronal que determinan cómo el modelo de lenguaje procesa y genera texto. Se aprenden durante el entrenamiento en grandes conjuntos de datos y esencialmente codifican el conocimiento del modelo en forma cuantificada. Por lo general, más parámetros permiten que el modelo capture capacidades de generación de lenguaje más complejas y matizadas, pero también requieren más recursos computacionales para entrenar y ejecutar.
Algunos de los modelos de lenguaje más importantes de la actualidad, como PaLM 2 de Google, tienen cientos de miles de millones de parámetros. El GPT-4 de OpenAI es se rumorea que tiene más de un billón de parámetros, pero distribuidos en ocho modelos de 220 mil millones de parámetros en una configuración mixta de expertos. Ambos modelos requieren GPU de centro de datos de alta resistencia (y sistemas de soporte) para funcionar correctamente.
Por el contrario, Microsoft apuntó a algo pequeño con Phi-3-mini, que contiene sólo 3.800 millones de parámetros y fue entrenado en 3,3 billones de tokens. Eso lo hace ideal para ejecutarlo en GPU de consumo o hardware de aceleración de IA que se puede encontrar en teléfonos inteligentes y computadoras portátiles. Es una continuación de dos modelos de lenguaje pequeño anteriores de Microsoft: fi-2lanzado en diciembre, y fi-1lanzado en junio de 2023.
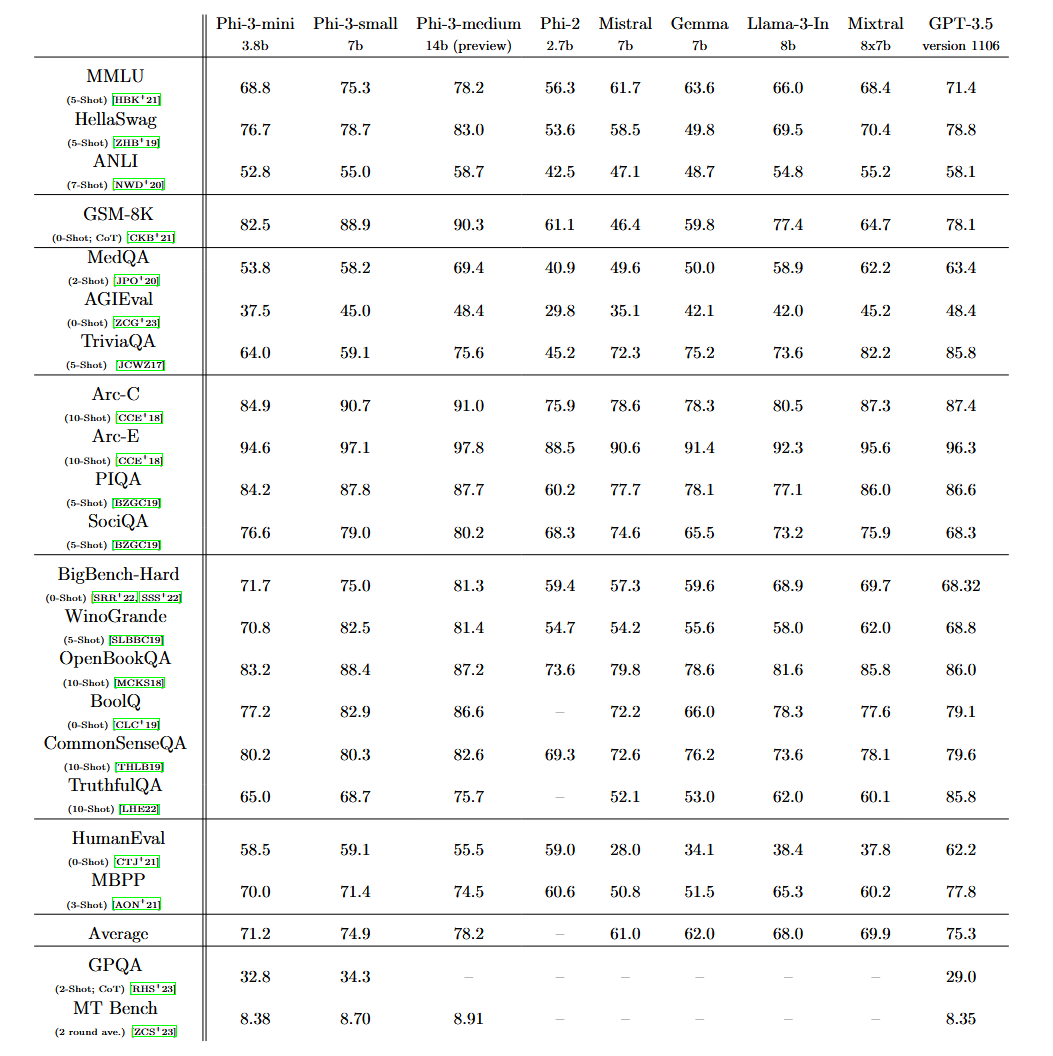
Phi-3-mini presenta una ventana contextual de 4000 tokens, pero Microsoft también introdujo una versión de 128K token llamada «phi-3-mini-128K». Microsoft también ha creado versiones de 7 mil millones y 14 mil millones de parámetros de Phi-3 que planea lanzar más adelante y que, según afirma, son «significativamente más capaces» que phi-3-mini.
Microsoft dice que Phi-3 presenta un rendimiento general que «rivaliza con el de modelos como Mixtral 8x7B y GPT-3.5″, como se detalla en un artículo titulado «Informe técnico de Phi-3: un modelo de lenguaje altamente capaz localmente en su teléfono.» Mixtral 8x7B, de la empresa francesa de inteligencia artificial Mistral, utiliza un modelo de combinación de expertos y GPT-3.5 impulsa la versión gratuita de ChatGPT.
«[Phi-3] Parece que va a ser un modelo pequeño sorprendentemente bueno si sus puntos de referencia reflejan lo que realmente puede hacer», dijo el investigador de IA Simon Willison en una entrevista con Ars. Poco después de proporcionar esa cita, Willison descargó Phi-3 en su computadora portátil Macbook. localmente y dijo: «Lo hice funcionar y está BIEN» en un mensaje de texto enviado a Ars.
Simón Willison
«La mayoría de los modelos que se ejecutan en un dispositivo local todavía necesitan un hardware pesado», dice Willison. «Phi-3-mini funciona cómodamente con menos de 8 GB de RAM y puede producir tokens a una velocidad razonable incluso con una CPU normal. Tiene licencia del MIT y debería funcionar bien en una Raspberry Pi de $ 55, y la calidad de los resultados que he visto hasta ahora es comparable a la de modelos 4 veces más grandes.«
¿Cómo logró Microsoft incluir una capacidad potencialmente similar a GPT-3.5, que tiene al menos 175 mil millones de parámetros, en un modelo tan pequeño? Sus investigadores encontraron la respuesta utilizando datos de entrenamiento de alta calidad y cuidadosamente seleccionados que inicialmente sacado de los libros de texto. «La innovación reside enteramente en nuestro conjunto de datos para entrenamiento, una versión ampliada del utilizado para phi-2, compuesto por datos web muy filtrados y datos sintéticos», escribe Microsoft. «El modelo también está más alineado en cuanto a solidez, seguridad y formato de chat».
Mucho se ha escrito sobre el potencial impacto medioambiental de los modelos de IA y los propios centros de datos, incluso en Ars. Con nuevas técnicas e investigaciones, es posible que los expertos en aprendizaje automático sigan aumentando la capacidad de modelos de IA más pequeños, reemplazando la necesidad de modelos más grandes, al menos para las tareas cotidianas. En teoría, eso no sólo ahorraría dinero a largo plazo, sino que también requeriría mucha menos energía en conjunto, lo que reduciría drásticamente la huella ambiental de la IA. Los modelos de IA como Phi-3 pueden ser un paso hacia ese futuro si los resultados de las pruebas comparativas resisten el escrutinio.
Phi-3 es Inmediatamente disponible en la plataforma de servicios en la nube de Microsoft, Azure, así como a través de asociaciones con la plataforma de modelos de aprendizaje automático Hugging Face y Ollamaun marco que permite que los modelos se ejecuten localmente en Mac y PC.



